MapReduce Job Life Cycle:
This section briefly sketches the life cycle of a MapReduce job and the roles of the primary actors in the life cycle. The full life cycle is much more complex. For details, refer to the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
Though other configurations are possible, a common Hadoop cluster configuration is a single master node where the Job Tracker runs, and multiple worker nodes, each running a Task Tracker. The Job Tracker node can also be a worker node.
- The local Job Client prepares the job for submission and hands it off to the Job Tracker.
- The Job Tracker schedules the job and distributes the map work among the Task Trackers for parallel processing.
- Each Task Tracker spawns a Map Task. The Job Tracker receives progress information from the Task Trackers.
- As map results become available, the Job Tracker distributes the reduce work among the Task Trackers for parallel processing.
- Each Task Tracker spawns a Reduce Task to perform the work. The Job Tracker receives progress information from the Task Trackers.
Job Client
Job Tracker
The Job Tracker is responsible for scheduling jobs, dividing a job into map and reduce tasks, distributing map and reduce tasks among worker nodes, task failure recovery, and tracking the job status. Job scheduling and failure recovery are not discussed here; see the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
The Job Tracker is responsible for scheduling jobs, dividing a job into map and reduce tasks, distributing map and reduce tasks among worker nodes, task failure recovery, and tracking the job status. Job scheduling and failure recovery are not discussed here; see the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
Task Tracker
Map Task
- Uses the
InputFormat to fetch the input data locally and create input key-value pairs.
- Applies the job-supplied map function to each key-value pair.
- Performs local sorting and aggregation of the results.
- If the job includes a
Combiner, runs the Combiner for further aggregation.
- Stores the results locally, in memory and on the local file system.
- Communicates progress and status to the Task Tracker.
Map task results undergo a local sort by key to prepare the data for consumption by reduce tasks. If a Combiner is configured for the job, it also runs in the map task. A Combiner consolidates the data in an application-specific way, reducing the amount of data that must be transferred to reduce tasks. For example, a Combiner might compute a local maximum value for a key and discard the rest of the values. The details of how map tasks manage, sort, and shuffle results are not covered here. See the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.
- Uses the
InputFormatto fetch the input data locally and create input key-value pairs. - Applies the job-supplied map function to each key-value pair.
- Performs local sorting and aggregation of the results.
- If the job includes a
Combiner, runs theCombinerfor further aggregation. - Stores the results locally, in memory and on the local file system.
- Communicates progress and status to the Task Tracker.
Map task results undergo a local sort by key to prepare the data for consumption by reduce tasks. If a
Combiner is configured for the job, it also runs in the map task. A Combiner consolidates the data in an application-specific way, reducing the amount of data that must be transferred to reduce tasks. For example, a Combiner might compute a local maximum value for a key and discard the rest of the values. The details of how map tasks manage, sort, and shuffle results are not covered here. See the documentation for your Hadoop distribution or the Apache Hadoop MapReduce documentation.Reduce Task
The reduce phase aggregates the results from the map phase into final results. Usually, the final result set is smaller than the input set, but this is application dependent. The reduction is carried out by parallel reduce tasks. The reduce input keys and values need not have the same type as the output keys and values.The reduce phase is optional. You may configure a job to stop after the map phase completes
- Fetches job resources locally.
- Enters the copy phase to fetch local copies of all the assigned map results from the map worker nodes.
- When the copy phase completes, executes the sort phase to merge the copied results into a single sorted set of
(key, value-list) pairs.
- When the sort phase completes, executes the reduce phase, invoking the job-supplied reduce function on each
(key, value-list)pair.
- Saves the final results to the output destination, such as HDFS.
The input to a reduce function is key-value pairs where the value is a list of values sharing the same key. For example, if one map task produces a key-value pair ('eat', 2) and another map task produces the pair ('eat', 1), then these pairs are consolidated into('eat', (2, 1)) for input to the reduce function. If the purpose of the reduce phase is to compute a sum of all the values for each key, then the final output key-value pair for this input is ('eat', 3). For a more complete example,
Output from the reduce phase is saved to the destination configured for the job, such as HDFS or MarkLogic Server. Reduce tasks use anOutputFormat subclass to record results. The Hadoop API provides OutputFormat subclasses for using HDFS as the output destination. The MarkLogic Connector for Hadoop provides OutputFormat subclasses for using a MarkLogic Server database as the destination. For a list of available subclasses, The connector also provides classes for defining key and value types.
The reduce phase aggregates the results from the map phase into final results. Usually, the final result set is smaller than the input set, but this is application dependent. The reduction is carried out by parallel reduce tasks. The reduce input keys and values need not have the same type as the output keys and values.The reduce phase is optional. You may configure a job to stop after the map phase completes
- Fetches job resources locally.
- Enters the copy phase to fetch local copies of all the assigned map results from the map worker nodes.
- When the copy phase completes, executes the sort phase to merge the copied results into a single sorted set of
(key, value-list)pairs. - When the sort phase completes, executes the reduce phase, invoking the job-supplied reduce function on each
(key, value-list)pair. - Saves the final results to the output destination, such as HDFS.
The input to a reduce function is key-value pairs where the value is a list of values sharing the same key. For example, if one map task produces a key-value pair
('eat', 2) and another map task produces the pair ('eat', 1), then these pairs are consolidated into('eat', (2, 1)) for input to the reduce function. If the purpose of the reduce phase is to compute a sum of all the values for each key, then the final output key-value pair for this input is ('eat', 3). For a more complete example,
Output from the reduce phase is saved to the destination configured for the job, such as HDFS or MarkLogic Server. Reduce tasks use an
OutputFormat subclass to record results. The Hadoop API provides OutputFormat subclasses for using HDFS as the output destination. The MarkLogic Connector for Hadoop provides OutputFormat subclasses for using a MarkLogic Server database as the destination. For a list of available subclasses, The connector also provides classes for defining key and value types.How Hadoop Partitions Map Input Data
When you submit a job, the MapReduce framework divides the input data set into chunks called splits using theorg.apache.hadoop.mapreduce.InputFormat subclass supplied in the job configuration. Splits are created by the local Job Client and included in the job information made available to the Job Tracker.
The JobTracker creates a map task for each split. Each map task uses a RecordReader provided by the InputFormat subclass to transform the split into input key-value pairs. The diagram below shows how the input data is broken down for analysis during the map phase:
The Hadoop API provides InputFormat subclasses for using HDFS as an input source. The MarkLogic Connector for Hadoop providesInputFormat subclasses for using MarkLogic Server as an input source. For a list of available MarkLogic-specific subclasses, seeInputFormat Subclasses.
org.apache.hadoop.mapreduce.InputFormat subclass supplied in the job configuration. Splits are created by the local Job Client and included in the job information made available to the Job Tracker.RecordReader provided by the InputFormat subclass to transform the split into input key-value pairs. The diagram below shows how the input data is broken down for analysis during the map phase: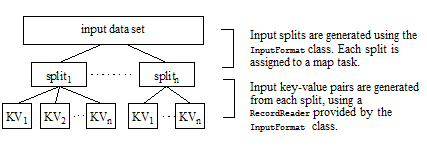
InputFormat subclasses for using HDFS as an input source. The MarkLogic Connector for Hadoop providesInputFormat subclasses for using MarkLogic Server as an input source. For a list of available MarkLogic-specific subclasses, seeInputFormat Subclasses.
No comments:
Post a Comment